Automating ISIC Code Classification with BERT
Transforming Economic Data Using Machine Learning at the Gambia Bureau of Statistics (GBoS)
May 10th, 2025 | Economic Statistics
The Classification Challenge That Demands Innovation
Accurate industrial classification is the backbone of modern economic intelligence. Every registered business, survey response, and policy decision relies on the precision of ISIC
(International Standard Industrial Classification) codes. Yet traditional manual classification faces significant challenges:
Manual Process Issues:
- Slow processing times: Classification specialists can process only 40-50 descriptions per day
- Human error prone: Fatigue and subjectivity lead to inconsistent classifications
- Inconsistent results: Different classifiers interpret identical business descriptions differently
Critical Need: Accurate ISIC classification is crucial for reliable statistics and informed policy decisions across industries. At the Gambia Bureau of Statistics (GBoS), we recognized that incremental improvements weren't enough. We needed a paradigm shift—a system that delivers speed, accuracy, explainability, and adaptability simultaneously.

Our Innovation: A Three-Tier AI Architecture
We built an AI classification system that seamlessly integrates the speed of deep learning, the transparency of retrieval-augmented generation, and the intelligence of large language models.
1. BERT: The Classification Engine
At the core of our system, BERT serves as the primary classifier:
2. RAG (Retrieval-Augmented Generation): The Knowledge Bridge
Once BERT predicts an ISIC code, RAG retrieves comprehensive contextual information:
- Indexes complete ISIC manual sections
-
Retrieves contextually relevant passages that explain each classification
-
Provides version-aware classification during transition periods between revisions
-
Brings explainability by grounding predictions in official documentation
3. LLM (LLaMA): The Explanation Generator
The LLM transforms technical predictions into human-readable insights:
- Converts retrieved sections into clear, natural language justifications
- Delivers confidence scoring and alternative classification suggestions
- Creates a full audit trail for every classification decision
- Enables non-technical users to understand and trust the system

How the System Works
1. Multilingual Input Processing
The system accepts descriptions in English, French, Spanish, Wolof, Portuguese, Arabic etc. It automatically detects the language and translates while preserving semantic meaning.
Example:
French Input: "Boulangerie artisanale produisant pain et pâtisseries"
→ Processed: "Artisan bakery producing bread and pastries"
2. BERT Prediction with Class Balancing
Weighted loss functions ensure rare categories (e.g., niche manufacturing sectors) receive appropriate attention during training.
Output:
Predicted Code: 1071 – Manufacture of bread and bakery products
Confidence: 90%
3. RAG Retrieval
The system pulls relevant ISIC manual sections to provide authoritative context.
Example (ISIC Rev. 4, Class 1071):
"Includes manufacture of fresh, frozen or dry bakery products such as bread, rolls, cakes, pies, pastries, waffles…"
4. LLM Explanation
The LLM synthesizes BERT's prediction and RAG's retrieved context into a clear justification.
Example Output:
"This business is classified as 1071 because it manufactures bakery products from raw ingredients. According to ISIC Rev. 4, Class 1071 covers manufacture of fresh bakery products including artisan operations. The activity is manufacturing rather than retail because production is the primary function."
Alternative Consideration: If the business mainly sells pre-made products, consider 4721 – Retail sale of food in specialized stores.
5. Human Review Loop
Real-World Impact: From Theory to Practice
The implementation of this system has transformed the classification workflow at GBoS with measurable results across multiple dimensions.
Efficiency Revolution
Our system has enabled a paradigm shift in classification efficiency:
- 500× Throughput Increase: From ~50 to ~25,000 descriptions per day on standard hardware
- 85% Resource Optimization: Staff time for classification reduced dramatically, allowing reallocation to quality control and analysis
- From Weeks to Minutes: Classification lag reduced from weeks to near real-time processing
- Scalable Capacity: Classification capacity flexes to meet seasonal demands without additional hiring
Quality Enhancements
Beyond efficiency gains, the system delivers significant qualitative improvements:
- Consistency Standardization: Uniform application of classification principles across all business activities
- Error Reduction: Elimination of human fatigue and subjective interpretation factors
- Emerging Category Identification: Better recognition of new and evolving business models
Resource Optimization
In resource-constrained environments, the system provides critical advantages:
- Reallocation of Expertise: Statistical staff focus on analysis and validation rather than routine classification
- Capacity Building: System implementation builds transferable AI skills within statistical offices
- Sustainable Operations: Reduced dependency on expensive external consultants

As demonstrated by our performance metrics, the AI-powered approach delivers consistent improvements across all key dimensions of the classification process, with particularly dramatic gains in processing speed and resource utilization.
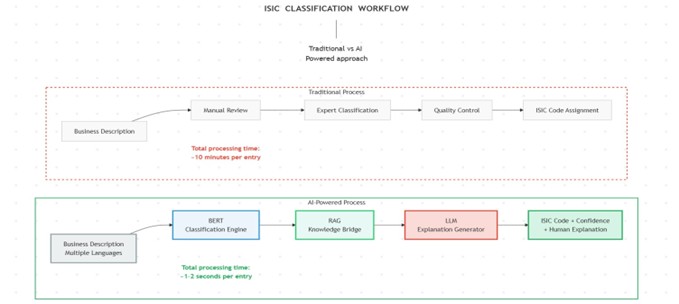
The Technology Behind the Innovation
Our solution leverages a sophisticated technical stack specified as below:
|
# Core model architecture
Model = ClassificationModel(
“bert”,
“google-bert/bert-base-uncased”,
args=model_args,
num_labels=len(label_encoder.classes_),
use_cuda=use_cuda,
cuda_device=cuda+device
)
|
The model employs a carefully designed training pipeline:
- Text Normalization: Comprehensive preprocessing to standardize business descriptions
- Label Encoding: Sophisticated encoding that preserves ISIC hierarchical relationships
- Inference Pipeline: Optimized prediction flow with confidence scoring and alternative suggestions
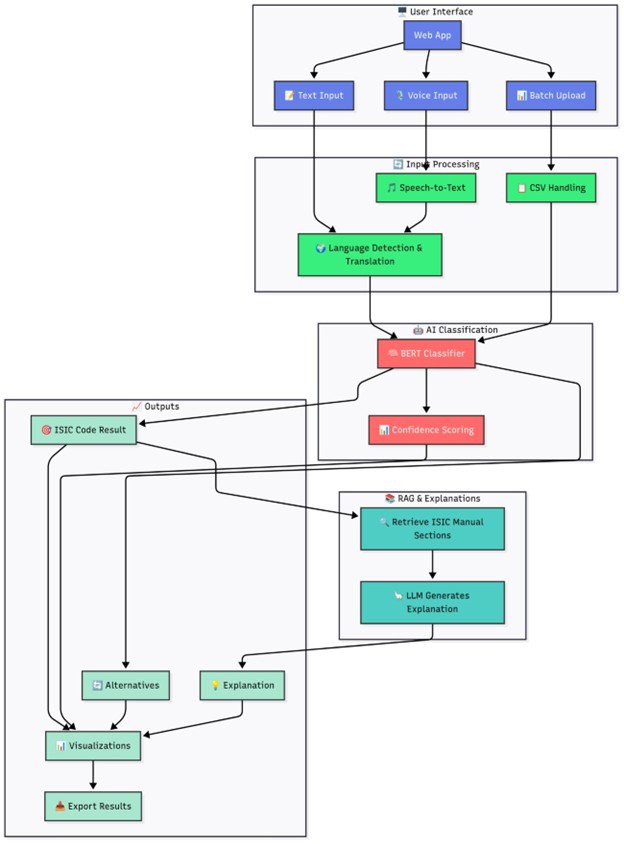
The complete implementation pipeline shown in the Figure above demonstrates how GBoS’s system integrates seamlessly into existing statistical workflows while providing multiple interfaces for different user needs.
User-Centric Design
We prioritized building an intuitive interface that makes advanced AI technology accessible to non-technical users.
Single-Entry Classification Interface
- Multiple Input Methods: Support for both text and voice input
- Real-Time Processing: Immediate feedback on classification results
- Confidence Visualization: Clear indicators of prediction reliability through color-coded confidence scores
- Alternative Suggestions: Ranked alternative classifications for ambiguous cases
Batch Processing Capabilities
For high-volume needs, the system includes robust batch processing:
- CSV Upload Integration: Simple processing of large datasets through drag-and-drop
- Comprehensive Output: Results include codes, descriptions, confidence metrics, and explanations
- Visualization Tools: Interactive distribution charts of classification results
Implementation & Accessibility
Implementation Requirements
Statistical offices interested in implementing this solution will find the technical requirements surprisingly modest:
Hardware:
- Standard server with 64GB RAM and modern CPU (GPU optional but recommended for faster processing)
Software:
- Python 3.8+, PyTorch, Transformers, Streamlit
Training Data:
- ~10,000 pre-classified business descriptions to fine-tune the model
Expertise:
- Python knowledge and statistical classification understanding
Deployment
- Timeline: ~5 weeks from initial setup to production deployment
Beyond ISIC: Future Applications
The framework extends naturally to other classification challenges faced by statistical offices:
Immediate Extensions:
-
ISCO Classification: Occupation classification using identical architecture
- CPC Classification: Product classification with minimal adaptation
- HS Codes: Trade classification for customs and commerce data
Planned Developments:
-
Mobile Deployment: Field-ready applications for on-site classification during surveys
- Registry Integration: Direct connections with business registry systems for real-time classification
- Multi-label Classification: Support for businesses with multiple distinct activities
- Anomaly Detection: Identification of suspicious or potentially misclassified entries
Lessons Learned
Technical Insights
Organizational Change
- Address job security concerns openly: Frame AI as augmentation, not replacement— emphasize how it elevates human expertise
- Involve expert classifiers: Include them in training, validation, and system refinement
- Celebrate quick wins: Build momentum through visible early successes
- Document everything: Ensure knowledge transfer and long-term sustainability
Conclusion: A New Paradigm for Statistical Classification
Our machine learning solution for ISIC code classification demonstrates how advanced AI techniques can transform fundamental statistical processes in resource-constrained environments. By achieving high accuracy with near-instantaneous processing times, the system addresses not only the immediate challenges of ISIC classification but establishes a framework for ongoing improvement and adaptation.
Statistical offices can leverage this approach to enhance data accuracy, timeliness, and consistency—ultimately improving the quality of economic statistics that inform critical policy decisions. This project proves that modern AI approaches are not exclusive to wealthy nations but can be practically implemented to solve real problems in statistical offices throughout the developing world.
Key Achievements
500× faster than manual methods
90% accuracy, even for rare codes
100% explainable with manual references
Multilingual and globally adaptable
Version-aware for seamless ISIC updates
Resources
GitHub Repository: https://github.com/BabaJasseh/Machine-Learningfor-ISIC-CodeClassification
Tags: Machine Learning, BERT, RAG, LLM, ISIC Classification, Economic Statistics, Natural Language Processing, AI for Development, Statistical Innovation, Explainable AI, GBoS, Africa